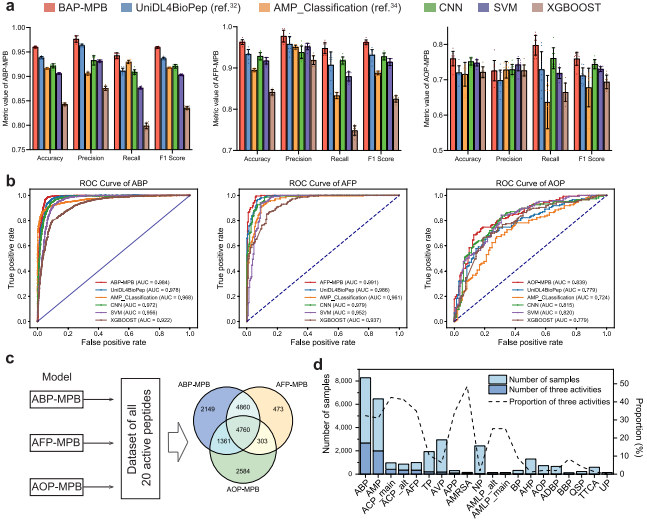
图2、 不同模型的对比性能以及基于ABP-MPB、AFP-MPB和AOP-MPB模型在全部20个数据集上的活性预测与多功能分析。a基于10折交叉验证结果(10折的平均值±标准差,n=10),在测试集上的预测性能。由训练好的BAP-MPB(即ABP-MPB、AFP-MPB和AOP-MPB)以及其他模型32,34得到准确率、精确率、召回率和F1分数,所有模型均在相同数据集上训练与评估。对于这四项指标而言,分数越高表明性能越好。b六种模型在ABP、AFP和AOP数据集上的ROC曲线,曲线下面积即为AUC。c由三个模型做出预测,仅保留预测为阳性的样本。最终展示三个模型阳性预测的交集,中心数字4760代表被三个模型均预测为具有生物活性的肽。d每个原始生物活性肽数据集中的阳性样本数量,以及被预测具有抗菌、抗真菌和抗氧化活性的样本数量(柱状图,左侧纵轴),还有每个数据集中具有三重活性的样本占比(折线图,右侧纵轴)。
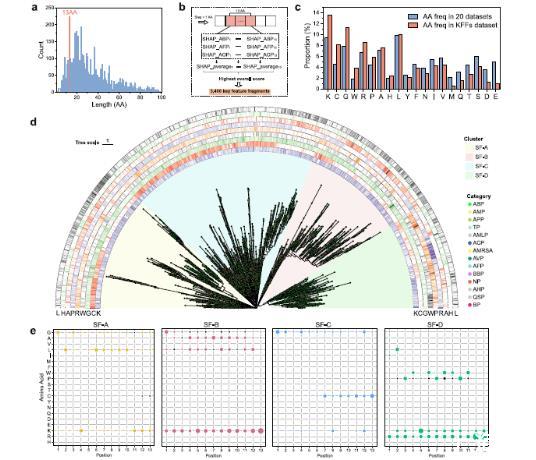
图3 、关键氨基酸特征与关键特征片段。a 20个生物活性肽数据集中阳性样本的长度分布,其中兼具潜在抗菌、抗真菌和抗氧化活性的4760个样本中,13个氨基酸长度的序列出现频率最高。b关键特征片段提取示意图。设置13个氨基酸的窗口,以1个氨基酸为步长在整条序列上进行滑动。选取平均SHAP值总和最高且分值大于0的片段。满足所有条件的3400个片段被作为关键特征片段进行重点研究。c关键特征片段中各氨基酸占比与全部20个数据集中各氨基酸占比的比较。d 3400个关键特征片段在系统发育树中呈现的四个亚家族分布情况,分别为亚家族A(SF-A)、亚家族B(SF-B)、亚家族C(SF-C)和亚家族D(SF-D)。分支末端的彩色圆点代表各关键特征片段对应的原始生物活性肽来源。e每个关键特征片段亚家族中13个位置上的氨基酸分布,每个位置上突出显示的是出现频率最高的前三种氨基酸。
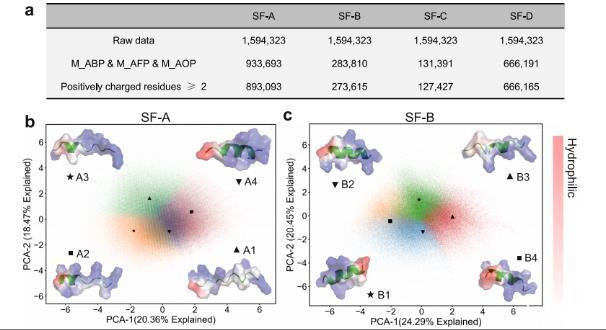
图4 、合理序列子空间中的筛选。a经过逐一严格筛选标准筛选后,亚家族A(SF-A)、亚家族B(SF-B)、亚家族C(SF-C)和亚家族D(SF-D)中剩余的序列数量。b–e各亚家族内部的聚类与代表性序列的筛选。在主成分分析图中,不同颜色的点代表不同的簇,黑色标记的点指示所选代表性序列的位置。周围的结构图描绘了每条所选代表性序列的三维结构:内部部分展示详细的三维结构,外部半透明部分展示该肽的疏水性分布。
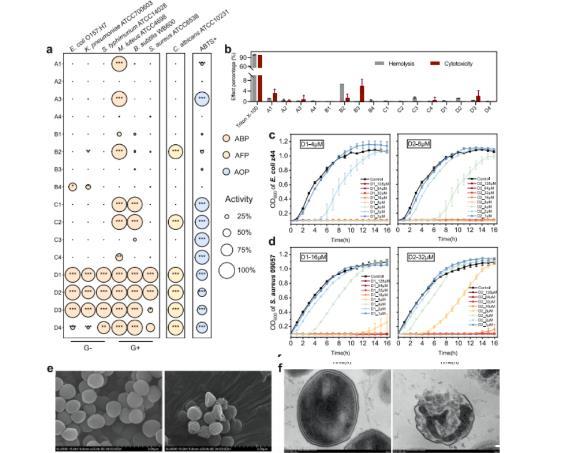
图5、 候选抗菌肽的实验验证与效价测定。a在128微摩尔浓度下对6种细菌和1种真菌菌株的抑制率,以及在1毫克/毫升浓度下对ABTS+自由基的清除率。b在128微摩尔浓度下评估16种候选抗菌肽的溶血活性和细胞毒性。曲拉通X-100作为阳性对照,磷酸盐缓冲液作为溶血活性的阴性对照,杜氏改良伊格尔培养基作为细胞毒性的对照。代表性耐药细菌的生长曲线,包括畜禽患病鸡中分离的大肠杆菌z44(c)以及临床环境中分离的金黄色葡萄球菌09057(d)。每组设置3次生物学独立重复(n=3),数据以平均值±标准差表示。对照组细菌正常生长。D1和D2的浓度梯度从128微摩尔开始以两倍梯度稀释,不同颜色代表不同浓度。每个图中标注的浓度为该肽对每种细菌的最低抑菌浓度。e磷酸盐缓冲液和64微摩尔D1处理的金黄色葡萄球菌09057的低倍扫描电镜图像(标尺,2微米)。f磷酸盐缓冲液和64微摩尔D1处理的金黄色葡萄球菌09057的低倍透射电镜图像(标尺,200纳米)。
总结
本论文解决当前深度学习方法设计抗菌肽(AMPs)成功率低、虚拟库规模大的挑战。其核心策略是利用深度学习模型的可解释性提取关键生物活性特征以指导新肽设计。研究团队基于预训练的蛋白质语言模型(MP-BERT),通过抗菌、抗真菌和抗氧化肽数据集微调得到三个独立的生物活性预测模型,并利用这些模型筛选出4760条潜在具有三重活性的肽段;随后,采用SHAP方法量化各氨基酸残基的贡献,从中提取了3400个13个氨基酸长度的关键特征片段(KFFs),并通过系统发育分析将其分为四个具有独特氨基酸频率特征的亚家族;针对每个亚家族,研究者提取每个位置频率最高的前三个氨基酸进行系统性排列组合,构建了有限的、富含关键特征的“合理序列子空间”,并最终从中筛选出16条代表性候选抗菌肽进行合成与验证。
在此过程中,芬兰Bioscreen C全自动微生物生长曲线分析仪发挥了高通量、自动化动态监测平台的关键作用,它通过精确控温和自动监测光密度,高效完成了对所有候选肽的最低抑菌浓度(MIC)测定,并生成了揭示抗菌作用动力学的完整时间-生长曲线,这些数据不仅定量证实了设计策略的高成功率(75%的肽至少具有两种活性),更特别凸显了肽D1和D2对包括多重耐药临床分离株在内的广谱强效抗菌活性,其中D1在体内败血症模型中还能有效降低细菌负荷并缓解炎症。微生物生长曲线数据的研究意义深远,它不仅是定量评价药效、确定MIC的核心指标,其动态变化形态还有助于推测作用机制(如本研究结合电镜证实D1通过破坏细胞膜实现快速杀菌),并可用于评估耐药性风险(如连续传代未诱导出对D1的耐药性)。
该研究通过DLFea4AMPGen平台,成功将深度学习模型学到的特征转化为具体设计规则,显著提高了设计成功率和效率,而Bioscreen仪器及其产生的生长曲线数据则构成了从计算机设计预测到高效实验验证、再到机制初步探索的完整证据链基础,共同加速了具有多重功能的新型抗菌肽的研发进程。
相关新闻推荐
3、生物炭与细菌微生物互作对小白菜生长的影响及益生菌的分离表征