研究简介
本研究解决了当前利用深度学习方法从头设计抗菌肽(AMPs)所面临的挑战,如设计成功率低、生成的虚拟肽库规模庞大等问题。为此,研究者开发了一种名为DLFea4AMPGen的新型策略。该策略的核心是利用深度学习模型的可解释性,提取与抗菌肽生物活性相关的关键特征,并基于这些特征指导新肽序列的设计。研究人员首先基于预训练的蛋白质语言模型(MP-BERT),利用已有的抗菌肽(ABP)、抗真菌肽(AFP)和抗氧化肽(AOP)数据集,微调得到了三个独立的生物活性预测模型(ABP-MPB, AFP-MPB, AOP-MPB)。接着,他们使用这三个模型对20个生物活性肽数据集中的两万余条肽段进行预测,筛选出被三个模型均预测为阳性的4760条潜在具有三重活性(抗菌、抗真菌、抗氧化)的肽段。为了理解模型决策并提取关键特征,研究者采用了SHAP(SHapley Additive exPlanations)方法,量化每个氨基酸残基对预测活性的贡献。
从上述多活性肽段中,他们提取了关键特征片段——即SHAP值总和最高的13个氨基酸长度的片段,共得到3400个KFFs。通过对这些KFFs进行系统发育树分析,研究者将其分为四个具有不同氨基酸频率特征的亚家族。本研究提出的DLFea4AMPGen平台,通过整合深度学习模型的预测能力与SHAP的可解释性分析,成功地将“黑箱”模型学习到的关键生物活性特征转化为具体的序列设计规则。这种方法不仅显著提高了从头设计抗菌肽的成功率,减少了需要筛选的虚拟序列空间规模,还能够直接设计具有多重生物功能(抗菌、抗真菌、抗氧化)的肽类分子,为针对耐药病原体的新型肽类疗法开发提供了一个高效的概念验证流程。
Bioscreen 全自动生长曲线分析仪的应用
测定最低抑菌浓度时,抗菌肽测试浓度从128微摩尔按两倍梯度稀释至1微摩尔。利用自动Bioscreen C全自动生长曲线分析仪(芬兰雷勃公司)监测细菌生长。系统在37℃孵育16小时,每10分钟测量一次光密度600。通过绘制生长曲线,观察肽对不同细菌的抗菌活性。全自动微生物生长曲线分析仪发挥了高通量、自动化动态监测平台的关键作用,它通过精确控温和自动监测光密度,高效完成了对所有候选肽的最低抑菌浓度(MIC)测定,并生成了揭示抗菌作用动力学的完整时间-生长曲线。数据不仅定量证实了设计策略的高成功率(75%的肽至少具有两种活性),更特别凸显了肽D1和D2对包括多重耐药临床分离株在内的广谱强效抗菌活性,其中D1在体内败血症模型中还能有效降低细菌负荷并缓解炎症。
实验结果
介绍了DLFea4AMPGen,一种用于抗菌肽生成的深度学习方法,可学习与肽生物活性相关的特征。与现有其他抗菌肽设计方法相比,DLFea4AMPGen可降低计算成本、提高设计成功率,并生成活性更多样的抗菌肽。通过SHAP分析,识别出对深度学习模型预测准确性影响最强的特征和物理因素,然后专门聚焦这些特征构建合理序列子空间。利用该序列空间从头设计抗菌肽,合成16条抗菌肽进行实验验证,检测到候选抗菌肽D1和D2具有强效广谱抗菌活性,包括对耐药菌株的活性。D1和D2的功效为验证本方法提供了概念验证证据,并支持进一步开发针对耐药病原体的治疗药物。
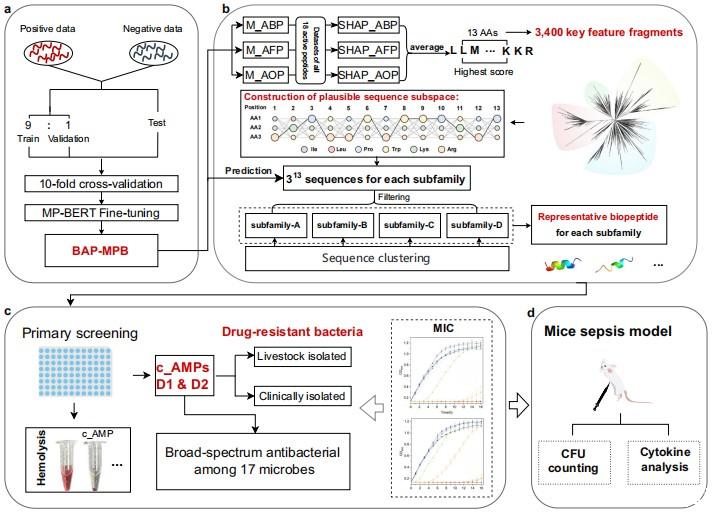
图1 、研究工作流程示意图。a首先利用前期研究中的生物活性肽数据集开展模型构建。通过对预训练的MP-BERT模型进行微调,开发了三种模型,分别为ABP-MPB、AFP-MPB和AOP-MPB,统称为BAP-MPB(基于MP-BERT的生物活性肽模型)。此外这三种模型被用于预测具有潜在三重活性的肽。b随后,基于对这三种模型的SHAP解释,采用13个氨基酸的滑动窗口,在被三种模型均预测为生物活性阳性的每条肽序列中,识别出平均SHAP值最高的关键特征片段。依据不同的氨基酸特征,这些关键特征片段被划分为四个亚家族,并且将每个位置上排名前三的高频氨基酸进行系统组合,形成所有可能的序列组合,以构建合理序列子空间。从每个合理序列子空间中选取代表性序列作为候选抗菌肽,用于化学合成。c、d针对小鼠脓毒症模型开展进一步的功效测试与机制分析。最低抑菌浓度实验设置三次生物学重复,数据以平均值±标准差表示,同时开展兼具体外抗菌和抗氧化活性的体内实验。
相关新闻推荐
2、乳酸乳球菌F44生长曲线、pH曲线、酸耐受、Nisin耐受和Nisin效价(一)